
AWS S3バケットにエクスポートされた録音を操作する
AWS S3録画一括アクション統合 を設定すると、Genesys Cloudにある録画をAWS S3バケットに一括でエクスポートすることができます。 このエクスポートは、QMポリシーによって自動的に、または録画バルクアクションAPIを呼び出すことによって明示的に実行することができます。
この記事では、AWS S3バケットにエクスポートされるコンテンツについて詳しく説明します。
AWS S3バケットの内容
録画ファイルは、AWS S3バケットに以下のような構造のフォルダにエクスポートされます。
s3://{bucket}/{organizationId}/year={year}/{month={month}/day={day}/hour={hourOfDay}/conversation_id={conversationId}/ (以下略
| プレースフォルダー | 説明 |
|---|---|
| {バケツ} | S3バケット名。 |
| {organizationId}。 | 組織IDです。 |
| {年}です。 | 会話が始まった年。 |
| {月}です。 | 会話が始まった月(数字で)。 |
| {day} | 会話が始まった日。 |
| {時間/日} |
会話が始まった時間帯。 |
| {conversationId}を指定します。 |
会話のIDです。 |
このフォルダーには、会話中に保持されるすべての録音ファイルが含まれています。 各録画ファイルには1つの録画があり、ファイル名が録画IDになります。
各録音ファイルには、対応するJSONメタデータファイルがあります。 JSONメタデータのファイル名の末尾には"_metadata.json "が付きます。
メタデータは、エクスポートされた録画の検索に使用できます。 詳しくは、Athena+Glueの例 (録画検索サービスの例)をご覧ください。
メタデータファイルは、以下のスキーマを持つJSON形式である。
{
“$schema”: “http://json-schema.org/draft-04/schema#”,
「タイプ」:「オブジェクト」
「プロパティ」: {
「メディアタイプ」: {
"説明":「メディアタイプ(通話、チャット、メール、メッセージ、画面のいずれか)」
「タイプ」:「文字列」
},
「メディアサブタイプ」: {
"説明":「録音のサブタイプ(トランク、ステーション、コンサルト、スクリーンのいずれか)」
「タイプ」:「文字列」
},
「メディア件名」: {
"説明":「録音の主題」
「タイプ」:「文字列」
},
「プロバイダー」: {
"説明":「記録のプロバイダーの種類(例:エッジ)」
「タイプ」:「文字列」
},
“userIds”: {
"説明":「ユーザーリスト」
「型」:「配列」、
「アイテム」: [
{
「タイプ」:「文字列」
}
]
},
“startTime”: {
"説明":「録音開始時間」
「タイプ」:「文字列」
},
“endTime”: {
"説明":「録音終了時間」
「タイプ」:「文字列」
},
“durationMs”: {
"説明":「録音時間」
「型」:「整数」
},
“initialDirection”: {
"説明":「会話の最初の方向(インバウンド/アウトバウンド)」
「タイプ」:「文字列」
},
「アニノーマライズ」: {
"説明":「アニ」
「タイプ」:「文字列」
},
「アニ表示可能」: {
"説明":「表示可能な形式のANI」
「タイプ」:「文字列」
},
「dnisNormalized」: {
"説明":「DNIS」、
「タイプ」:「文字列」
},
“dnisDisplayable”: {
"説明":「表示可能な形式のDNIS」
「タイプ」:「文字列」
},
“queueIds”: {
"説明":「録音のキューIDのリスト」
「型」:「配列」、
「アイテム」: [
{
「タイプ」:「文字列」
}
]
},
“wrapupCodes”: {
"説明":「会話のまとめコード」
「型」:「配列」、
「アイテム」: [
{
「タイプ」:「文字列」
}
]
},
“organizationId”: {
"説明":「会話の一意のID」
「タイプ」:「文字列」
},
“conversationId”: {
"説明":「会話に関連付けられた一意のID」
「タイプ」:「文字列」
},
“conversationStartTime”: {
"説明":「会話の開始時間」
「タイプ」:「文字列」
},
“conversationEndTime”: {
"説明":「会話の終了時間」
「タイプ」:「文字列」
},
“recordingId”: {
"説明":「録音の固有ID」
「タイプ」:「文字列」
},
“filePath”: {
"説明":「録音のオリジナルパス」
「タイプ」:「文字列」
},
“fileSize”: {
"説明":「録音ファイルサイズ」
「型」:「整数」
},
“messageType”: {
"説明":「メッセージの発信元となるメッセージプラットフォームの種類(例:SMS、Twitter、Line、Facebook、WhatsApp、Webメッセージ、Open、Instagram)」
「タイプ」:「文字列」
},
“languageIds”: {
"説明":「言語の識別子」
「型」:「配列」、
「アイテム」: [
{
「タイプ」:「文字列」
}
]
},
“screenInformation”: {
"説明":「画面固有の情報には、画面ID、XとYの位置、解像度情報が含まれます」
「タイプ」:「オブジェクト」
}
},
"必須": [
「メディアタイプ」
「プロバイダー」
“startTime”,
“endTime”,
“durationMs”,
“organizationId”,
“conversationId”,
“conversationStartTime”,
“conversationEndTime”,
“recordingId”,
“filePath”,
“fileSize”
]
}
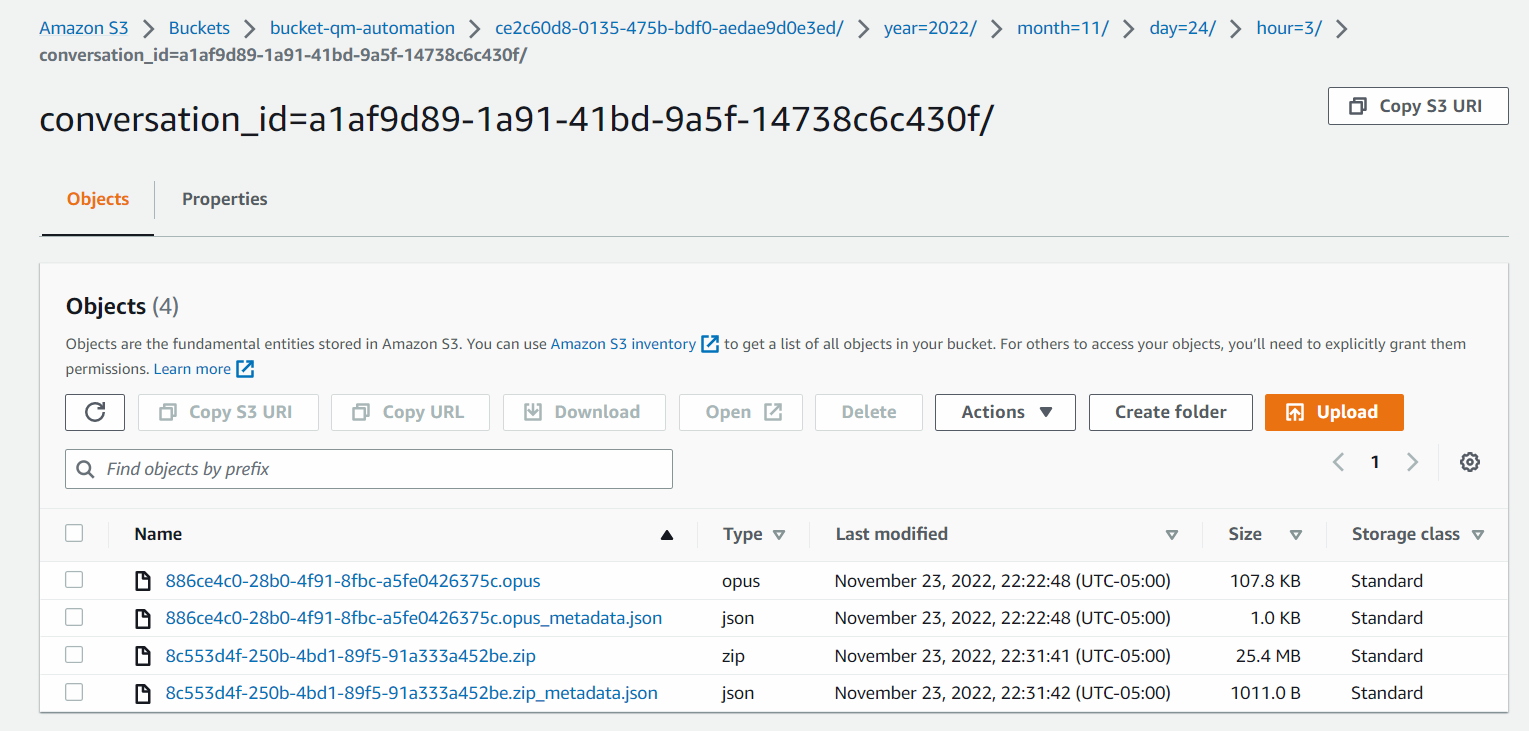
例えば、画面録画を有効にした通話会話には、以下のようなフォルダの内容が含まれる場合があります。
下の画像では、.opusファイルが音声録音ファイル、.zipファイルが画面録音ファイル、.jsonファイルがそれぞれのメディアファイルに関連するJSONメタデータです。
画像をクリックして拡大します。
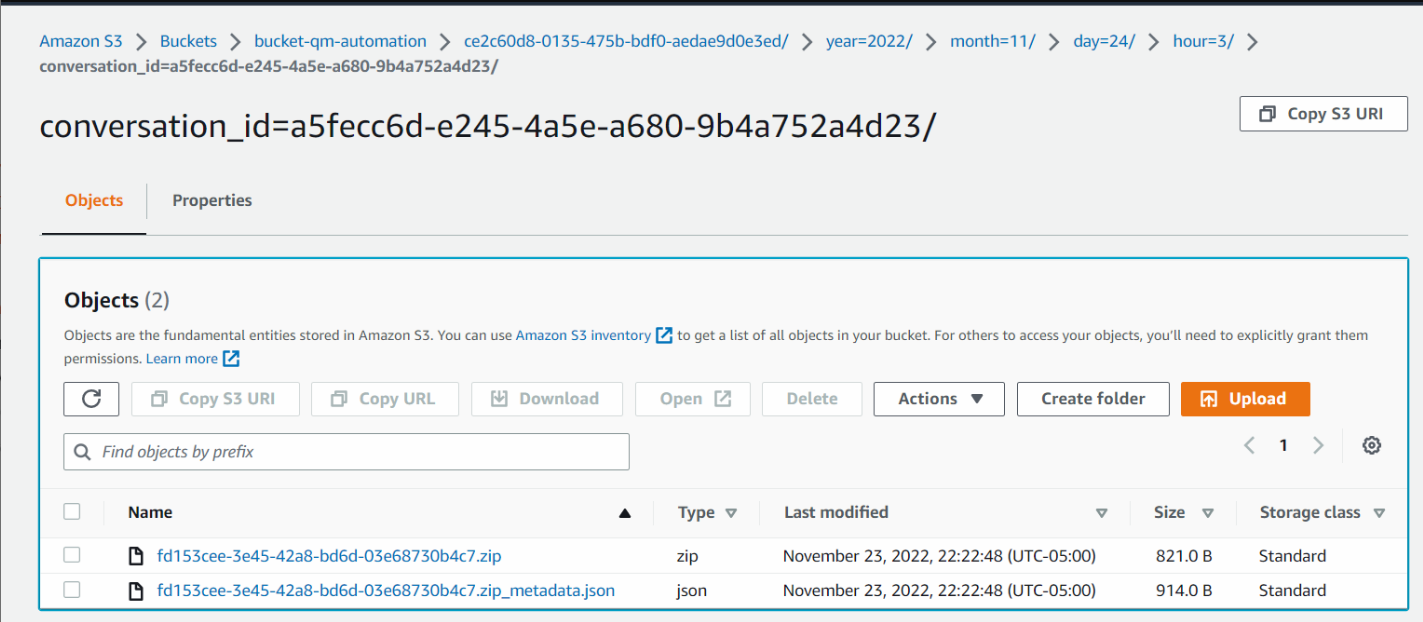
デジタル会話は、以下のようなフォルダの内容を持つことがあります。
下の画像では、.zipファイルにデジタル録音ファイル、.jsonファイルに対応するJSONファイルが格納されています。
画像をクリックして拡大します。
暗号化
S3バケットには、すでにAWS S3 Server-Side Encryption (SSE) が設定されています。 Amazon S3が管理する暗号鍵(SSE-S3)で有効化されているか、AWSが管理する鍵で有効化されているか、AWS Key Management Service(SSE-KMS)からお客様提供の鍵 で有効化されている可能性があります。
AWS S3 Server-Side Encryption (SSE) は、S3バケットに静止している録画ファイルを保護します。 バケットからファイルを取得する際、AWSは自動的にファイルの内容を復号化する。
システムに追加で有効化されたRecording Export Encryption が含まれている場合、S3バケットからファイルを取得した後、自分でファイル内容を復号化する必要があります。